Non-blocking and async Micronaut - quick start (part 2)
Welcome to the part 2 of "Non-blocking and async Micronaut" article. In the previous part we have explained the idea behind this demo and we have implemented product-service - a simple endpoint that returns information about some products. Today we will focus on implementing recommendations-service part and we will run some simple benchmark tests. Let’s start!
- Author
- Published
- Reading time8 minutes
- Discussion

| Source code can be found here: wololock/micronaut-nonblocking-async-demo |
Implementing recommendations-service
We use recommendation-service example more like an excuse to connect with product-service over HTTP. We won’t spent time on inventing recommendations algorithm - we will simply mock and hard-code products to recommend instead. This is fine for demo purpose and it allows us to focus on what is most important here - service to service communication over HTTP.
We will represent concept of recommendations-service as a single controller class stored in the separate package:
recommendation
└── RecommendationController.javaLet’s take a look at its implementation:
package com.github.wololock.micronaut.recommendation;
import com.github.wololock.micronaut.products.Product;
import com.github.wololock.micronaut.products.ProductClient;
import io.micronaut.http.annotation.Controller;
import io.micronaut.http.annotation.Get;
import io.reactivex.Observable;
import io.reactivex.Single;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Arrays;
import java.util.List;
@Controller("/recommendations")
final class RecommendationController {
private static final Logger log = LoggerFactory.getLogger(RecommendationController.class);
private static final List<String> ids = Arrays.asList( (1)
"PROD-001",
"PROD-002",
"PROD-003",
"PROD-004"
);
private final ProductClient productClient; (2)
public RecommendationController(ProductClient productClient) {
this.productClient = productClient;
}
@Get
public Single<List<Product>> getRecommendations() { (3)
log.debug("RecommendationController.getRecommendations() called...");
return Observable.fromIterable(ids) (4)
.flatMap(id -> productClient.getProduct(id).toObservable()) (5)
.toList(); (6)
}
}| 1 | A fixed list of 4 products IDs. |
| 2 | We use injected ProductClient - Micronaut will generate and compile a client class based on the interface. |
| 3 | We return Single<List<Product>> - a reactive type that represents some single value. |
| 4 | We start with converting list of IDs to Observable<String> |
| 5 | Next we map every ID to a corresponding Product retrieved via HTTP request. |
| 6 | We specify the return type to a Single<List<Product>>. |
The class is very concise as you can see. We start with injection of an implementation of ProductClient interface we have defined in product-service:
package com.github.wololock.micronaut.products;
import io.micronaut.http.annotation.Get;
import io.micronaut.http.client.annotation.Client;
import io.reactivex.Maybe;
@Client("/product")
public interface ProductClient {
@Get("/{id}")
Maybe<Product> getProduct(final String id);
}We don’t implement this interface explicitly - Micronaut takes care of generating implementing class at the compile time.
The getRecommendations method implements our business logic - it takes a list of IDs and for each ID it calls ProductClient.getProduct(id) and converts Maybe<Product> to Observable<Product> with toObservable() method call. And the last line of this method precises that we want to return a list of products and that’s it.
Let’s see it in action. We will start with a single HTTP request (using HTTPie):
% http localhost:8080/recommendations
HTTP/1.1 200 OK
Date: Fri, 26 Oct 2018 18:31:41 GMT
connection: keep-alive
content-length: 240
content-type: application/json
[
{
"id": "PROD-001",
"name": "Micronaut in Action",
"price": 29.99
},
{
"id": "PROD-002",
"name": "Netty in Action",
"price": 31.22
},
{
"id": "PROD-003",
"name": "Effective Java, 3rd edition",
"price": 31.22
},
{
"id": "PROD-004",
"name": "Clean Code",
"price": 31.22
}
]We get 4 recommendations in response as expected. And the console log of the application looks like this:
18:31:40.007 [nioEventLoopGroup-1-2 ] DEBUG - RecommendationController.getRecommendations() called...
18:31:40.173 [nioEventLoopGroup-1-2 ] DEBUG - ProductController.getProduct(PROD-001) executed...
18:31:40.175 [nioEventLoopGroup-1-2 ] DEBUG - ProductController.getProduct(PROD-003) executed...
18:31:40.178 [nioEventLoopGroup-1-2 ] DEBUG - ProductController.getProduct(PROD-002) executed...
18:31:40.178 [nioEventLoopGroup-1-2 ] DEBUG - ProductController.getProduct(PROD-004) executed...
18:31:40.297 [RxCachedThreadScheduler-1 ] DEBUG - Product with id PROD-001 ready to return...
18:31:40.368 [RxCachedThreadScheduler-3 ] DEBUG - Product with id PROD-002 ready to return...
18:31:40.777 [RxCachedThreadScheduler-2 ] DEBUG - Product with id PROD-003 ready to return...
18:31:41.379 [RxCachedThreadScheduler-4 ] DEBUG - Product with id PROD-004 ready to return...It took 1372 milliseconds to complete the request. We still use a single event-loop for a computation - that is why nioEventLoopGroup-1-2 handled the first 5 requests without blocking. If we process these requests in a blocking manner we would see something like this:
RecommendationController.getRecommendations() called...
ProductController.getProduct(PROD-001) executed...
Product with id PROD-001 ready to return...
ProductController.getProduct(PROD-003) executed...
Product with id PROD-002 ready to return...
ProductController.getProduct(PROD-002) executed...
Product with id PROD-003 ready to return...
ProductController.getProduct(PROD-004) executed...
Product with id PROD-004 ready to return...And it would not take 1372 ms but at least 2110 ms (a sum of latencies). Alternatively we would need at least 5 threads to handle this single request to /recommendations endpoint - one thread per connection. I think it shows clearly what is the difference between blocking and non-blocking approach.
Simulating multiple requests
Handling a single request on /recommendations endpoint isn’t very challenging for our demo application. Let’s see what happens if 500 concurrent requests (from 2000 total) reaches the application. To run such test we will use Apache HTTP benchmark tool:
ab -c 500 -n 2000 http://localhost:8080/recommendationsThis command executes 500 concurrent requests and does it 4 times (2000 requests in total).
This is ApacheBench, Version 2.3 <$Revision: 1826891 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking localhost (be patient)
Completed 200 requests
Completed 400 requests
Completed 600 requests
Completed 800 requests
Completed 1000 requests
Completed 1200 requests
Completed 1400 requests
Completed 1600 requests
Completed 1800 requests
Completed 2000 requests
Finished 2000 requests
Server Software:
Server Hostname: localhost
Server Port: 8080
Document Path: /recommendations
Document Length: 240 bytes
Concurrency Level: 500
Time taken for tests: 7.078 seconds
Complete requests: 2000
Failed requests: 65
(Connect: 0, Receive: 0, Length: 65, Exceptions: 0)
Non-2xx responses: 65
Total transferred: 730605 bytes
HTML transferred: 473370 bytes
Requests per second: 282.57 [#/sec] (mean)
Time per request: 1769.468 [ms] (mean)
Time per request: 3.539 [ms] (mean, across all concurrent requests)
Transfer rate: 100.80 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 3 5.6 0 23
Processing: 436 1376 278.3 1290 1953
Waiting: 436 1376 278.3 1290 1953
Total: 444 1379 281.1 1290 1961
Percentage of the requests served within a certain time (ms)
50% 1290
66% 1379
75% 1433
80% 1703
90% 1811
95% 1870
98% 1943
99% 1956
100% 1961 (longest request)Nothing unexpected happened. Median processing time per request is 1290 ms, which is OK - the longest request to product-service takes 1200 ms, so recommendations-service cannot return a response in shorter time. The longest request took 1961 ms - a decent and acceptable value in this demo.
The most interesting value is not shown directly in this result. We have executed 2000 requests to /recommendations endpoint and it took 7 seconds to complete all requests. However, our application handled not 2000, but 10,000 requests, because every single request to /recommendations causes 4 additional requests to /product/PROD-xxx, handled by the same application. It means that our demo application handled ~1429 requests per second. With just a single thread.
Another good information is that handling 10,000 request didn’t cause significant resources consumption. Below you can find a screen shot taken from JProfiler attached to the application when I have repeated the same ab command 3 times:
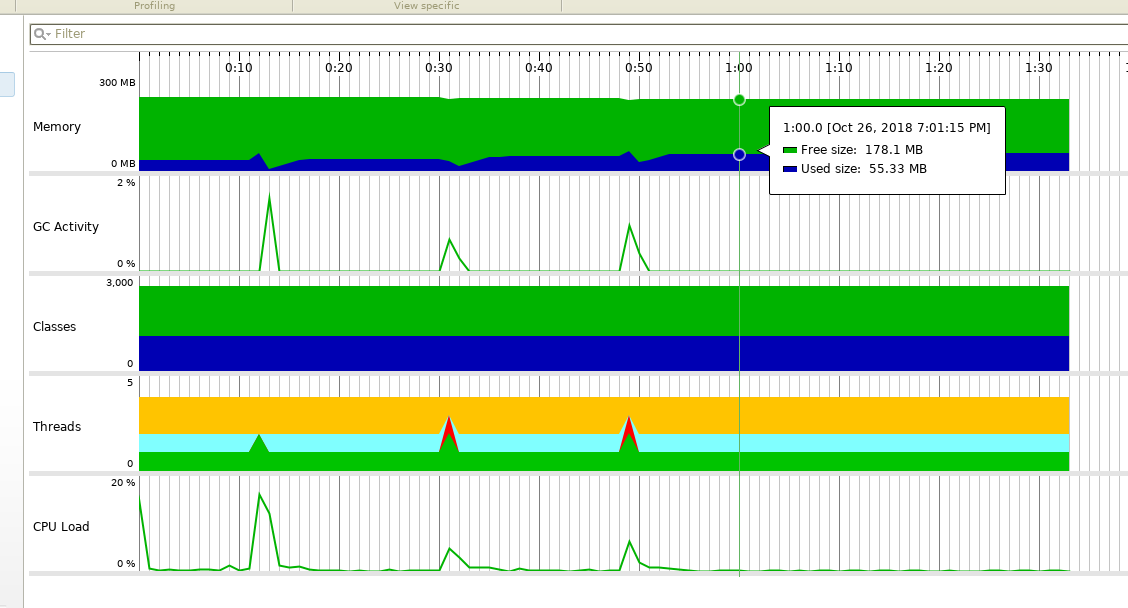
3 spikes on GC activity and CPU load (up to <20% max), and unnoticeable memory consumption increase. Keep in mind that this is not a bulletproof benchmark - I used application running with gradle run and I haven’t set any useful JVM tweak flags.

Building command-line app with Java 11, Micronaut, Picocli, and GraalVM | #micronaut
In this video, I will show you how to create a standalone command-line application (CLI app) using Java 11, Micronaut, Picocli, and GraalVM. We are going to build from scratch a Java program, and in the end, we will compile it to the native binary executable file you can run without the Java Virtual Machine. This is not a deep dive tutorial. It's a quickstart introduction to the technology to give you a better understanding about what Micronaut, Picocli, and GraalVM are suitable for. Watch now »
Conclusion
Part 2 ends here. In the next (and last) part of this article we will play around with timeouts and see what kind of problems it may introduce. Stay tuned, and until the next time!
| Continue reading here - Non-blocking and async Micronaut - quick start (part 3) |



0 Comments