Divide a list to lists of n size in Java 8
Every Java developer works with lists daily. There are many popular list (or collection) operations implemented in the standard Java 8 library, but there is one that is useful and commonly used, yet missing - partitioning. In this blog post, I would like to show you how you can split any list into chunks of fixed size without using any 3rd party library. Let’s start!
- Author
- Published
- Reading time9 minutes
- Discussion


Introduction
Partitioning (also known as chunking) is an operation that transforms a collection of elements into a collection of chunks of a given size. For instance, let’s say we have a list of 7 elements (incrementing numbers from 1 to 7) and we want to split it into a list of chunks of size 2.
[1,2,3,4,5,6,7] -> [[1,2], [3,4], [5,6], [7]]Let’s implement this operation using a new type of list, called Partition. We will extend the AbstractList<List<T>> class, and we will implement two methods - get(int index) and size(). The whole idea here is to hide the original list inside this class and modify its behavior, so instead of returning single elements from the original list, we are going to return chunks of a given size. Let’s take a look at the code and the following example to make this concept much easier to understand.
package com.github.wololock;
import java.util.AbstractList;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collection;
import java.util.List;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.stream.Collectors;
public final class Partition<T> extends AbstractList<List<T>> {
private final List<T> list;
private final int chunkSize;
public Partition(List<T> list, int chunkSize) {
this.list = new ArrayList<>(list);
this.chunkSize = chunkSize;
}
public static <T> Partition<T> ofSize(List<T> list, int chunkSize) {
return new Partition<>(list, chunkSize);
}
@Override
public List<T> get(int index) {
int start = index * chunkSize;
int end = Math.min(start + chunkSize, list.size());
if (start > end) {
throw new IndexOutOfBoundsException("Index " + index + " is out of the list range <0," + (size() - 1) + ">");
}
return new ArrayList<>(list.subList(start, end));
}
@Override
public int size() {
return (int) Math.ceil((double) list.size() / (double) chunkSize);
}
}All we have to do is to override those two methods, and our list of elements starts behaving like a list of chunks of the input elements. Those overridden methods affect methods like toString(), forEach(), or iterator(). Let’s take a look at a simple usage example to see how this Partition object behaves:
final List<Integer> numbers = Arrays.asList(1,2,3,4,5,6,7);
System.out.println(Partition.ofSize(numbers, 3));
System.out.println(Partition.ofSize(numbers, 2));Running this example will produce the following input to the console:
[[1, 2, 3], [4, 5, 6], [7]]
[[1, 2], [3, 4], [5, 6], [7]]
Why bother with creating a new class?
We can also ask ourselves if creating such a Partition class is mandatory. Maybe there is an alternative way to achieve the same effect without using 3rd party libraries? Well, the good news is - there are at least two different ways to get the same result. Let’s take a look at the first of them.
Imperative for-loop
If we are OK with the imperative programming style, we can use Java’s for-loop and do the partitioning while iterating the input list. In this case, we need to control if the given number belongs to the existing chunk or does it belong to the next one (by its index number). The code could look like this:
final List<Integer> numbers = Arrays.asList(1,2,3,4,5,6,7);
final int chunkSize = 3;
final AtomicInteger counter = new AtomicInteger();
for (int number : numbers) {
if (counter.getAndIncrement() % chunkSize == 0) {
result.add(new ArrayList<>());
}
result.get(result.size() - 1).add(number);
}
System.out.println(result);It produces the following console output:
[[1, 2, 3], [4, 5, 6], [7]]Using Java 8 Stream API + grouping collector
Alternatively, we could use Java 8 Stream API and its Collectors.groupingBy() collector method. Using this method we produce a map from a stream, but we can invoke values() method on the final map to get a collection of all its values. Then we can decide if we want to stay with the Collection<List<T>> or if we want to cast it to List<List<T>> by passing the collection to the, e.g. ArrayList<T> constructor. Below you can find an exemplary code.
final List<Integer> numbers = Arrays.asList(1,2,3,4,5,6,7);
final int chunkSize = 3;
final AtomicInteger counter = new AtomicInteger();
final Collection<List<Integer>> result = numbers.stream()
.collect(Collectors.groupingBy(it -> counter.getAndIncrement() / chunkSize))
.values();
System.out.println(result);Less lines of code, but the same console output:
[[1, 2, 3], [4, 5, 6], [7]]Which method to chose?
Now you may wonder - which method is the best? Should we use the Partition class, or is it better to use a good old imperative style that is quite easy to read and reason about? It depends. There is one significant difference between the first approach and the remaining two - the efficiency. Partitioning very small lists won’t make a big difference, but it starts making a huge (I mean huuuuge) difference when we start to play with large and larger lists. Let’s not speculate, but look at the numbers instead.
I created benchmark tests using JMH for the following scenarios:
partitioning 20 elements list into chunks of size 3,
partitioning 10,000 elements list into chunks of size 23,
and finally, partitioning 10,000,000 elements list into chunks of size 1024.
We will measure the efficiency of 4 different methods:
partitioning with the
Partitionclass,partitioning with the imperative for-loop,
partitioning with the Java 8 Stream API and
Collectors.groupingBy(),partitioning with the Java 8 Stream API with a custom collector that makes use of
Partitionclass.
All measurements use microsecond unit of time. (1 μs is equal to 0.001 ms and 0.000001 s).
All benchmark tests can be found in the wololock/java-performance-benchmarks Github repository. Feel free to clone the repository and run benchmarks on your own computer with the following command: I’ve run tests on a Lenovo ThinkPad T440p laptop with Intel® Core™ i7-4900MQ CPU @ 2.80GHz and 16 GBs RAM. I used JDK 1.8.0_201 (Java HotSpot™ 64-Bit Server VM, 25.201-b09). Below you can find JMH settings used for each benchmark test case: |
Here are the benchmark tests results.
Benchmark Mode Cnt Score Error Units
JavaListPartitionBenchmark.A1_smallListImperative avgt 42 0,501 ± 0,002 us/op
JavaListPartitionBenchmark.A2_smallListStreamGroupingBy avgt 42 0,637 ± 0,004 us/op
JavaListPartitionBenchmark.A3_smallListStreamPartitioned avgt 42 0,311 ± 0,004 us/op
JavaListPartitionBenchmark.A4_smallListToPartition avgt 42 0,132 ± 0,006 us/op
JavaListPartitionBenchmark.B1_largeListImperative avgt 42 173,364 ± 2,818 us/op
JavaListPartitionBenchmark.B2_largeListStreamGroupingBy avgt 42 255,984 ± 0,540 us/op
JavaListPartitionBenchmark.B3_largeListStreamPartitioned avgt 42 65,313 ± 0,387 us/op
JavaListPartitionBenchmark.B4_largeListToPartition avgt 42 4,686 ± 0,011 us/op
JavaListPartitionBenchmark.C1_hugeListImperative avgt 42 154043,254 ± 2497,491 us/op
JavaListPartitionBenchmark.C2_hugeListStreamGroupingBy avgt 42 249341,828 ± 842,087 us/op
JavaListPartitionBenchmark.C3_hugeListStreamPartitioned avgt 42 91150,418 ± 1079,959 us/op
JavaListPartitionBenchmark.C4_hugeListToPartition avgt 42 8737,578 ± 138,671 us/opLet’s look at those results more closely and see what do they look like as graphs.

The first benchmark tests a small list of 20 elements. As you can see, in this case, it doesn’t make a big difference which approach we choose. The difference between the fastest and the slowest approach is equal to 0.369 microseconds.

However, things start to change when we have to deal with lists containing thousands of elements. The slowest method requires 255 microseconds to complete (0.255 ms), while the fastest method is almost 64 times more efficient and it needs only 4 microseconds to do its job (0.004 ms). At this point, you can start thinking about the efficiency of available solutions. The context still matters - if you perform partitioning operation rarely, you might not need the fastest method to do the job efficiently.
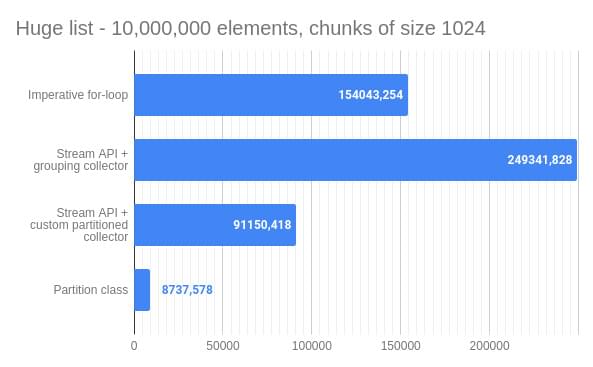
The final benchmark has only a single winner - the Partition class method. In this case, the slowest method takes almost 249341 microseconds (~250 ms), while the fastest method does the same job in 8737 microseconds (8.737 ms). However, the gap between both methods decreased to the size of 28 times. It happens mostly because the Partition class creates a copy of the input list. If we use a reference to the existing list instead of creating its copy, we could reduce 8737 microseconds to less than 2 microseconds. It could be quite risky - using a reference instead of a copy means that whenever the input list changes outside the context of Partition class, it changes our partitioned list.

Building command-line app with Java 11, Micronaut, Picocli, and GraalVM | #micronaut
In this video, I will show you how to create a standalone command-line application (CLI app) using Java 11, Micronaut, Picocli, and GraalVM. We are going to build from scratch a Java program, and in the end, we will compile it to the native binary executable file you can run without the Java Virtual Machine. This is not a deep dive tutorial. It's a quickstart introduction to the technology to give you a better understanding about what Micronaut, Picocli, and GraalVM are suitable for. Watch now »
What if I want to use a 3rd party library?
That’s completely fine. There are at least two libraries that provide list partitioning operation, using a similar method to the Partition class one.
When you decide to use any of these two, be aware that they don’t create a copy of the input list. To avoid some nasty side effects, you may always want to pass a copy of a list instead.
Lists.partition(new ArrayList<>(numbers), 3);

0 Comments