How to catch curl response in Jenkins Pipeline?
In this blog post, I explain why you may want to use curl command in your Jenkinsfile, how to catch curl response and store it in a variable, as well as how to read HTTP response status code and extract some data from the JSON document. Enjoy!
- Author
- Published
- Reading time11 minutes
- Discussion

Why use curl instead of any Java HTTP client?
I guess you may ask this question: "why to bother with curl while there is Java or Groovy HTTP client I can use in the pipeline script block?". This question might look reasonable. However, there is one important fact you need to consider. Any Groovy (or Java) code you put into the script block is always executed on the Jenkins master server. No matter what agent/node you use to execute the specific stage(s). Now imagine the following scenario. Let’s say you have a dedicated node in your Jenkins infrastructure to run some REST API calls to perform a production deployment. And let’s assume that only this specific node can make such an HTTP call for security reasons. If you implement the deployment part by using some Groovy code (e.g., something as simple as java.net.HttpURLConnection), it will fail. The server that de facto makes an HTTP call, in this case, is not your dedicated node, but the Jenkins master server. The same one that is not allowed to make any connection to your production server(s). However, if you use the pipeline’s sh step to execute the curl command instead, the HTTP request will be sent from the designated Jenkins node. This way, you can design a topology where only a specific node can perform strategic REST API calls.
Now when you know "why", let’s take a look at the "how" part.

Capturing sh output with returnStdout option
The way to execute curl command is to use sh (or bat if you are on the Windows server) step. You need to know that the sh step by default does not return any value, so if you try to assign it’s output to a variable, you will get the null value. To change this behavior, you need to set the returnStdout parameter to true. In the following example, I use my local Jenkins installation to get the build information of one of my Jenkins pipelines using the JSON API endpoint.
pipeline {
agent any
stages {
stage("Using curl example") {
steps {
script {
final String url = "http://localhost:8080/job/Demos/job/maven-pipeline-demo/job/sdkman/2/api/json"
final String response = sh(script: "curl -s $url", returnStdout: true).trim()
echo response
}
}
}
}
}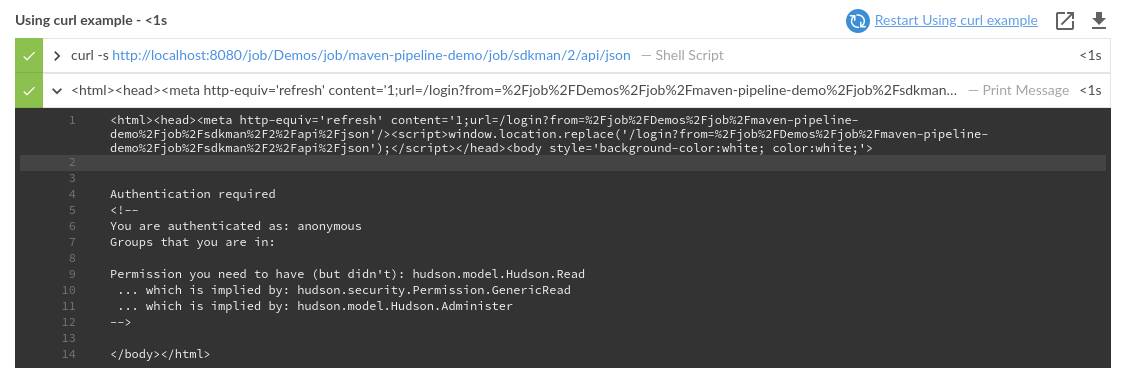
It is useful to call trim() on the output from the sh step to remove any new line characters. |
Using authentication
The endpoint I was trying to call in the previous example requires authentication. We can extend this example by adding -u username:password option and using Credentials Binding plugin to store those credentials.
Storing sensitive credentials securely is very difficult, and it is out of this blog post’s scope. However, here are a few hints that may help you avoid some real problems.
You can read more about securing sensitive credentials here: |
In this example, I use the user’s API Token instead of a real password. It works like a regular password, but it can be easily revoked, and the new one can be re-generated if needed. Also, you can use usernameColonPassword to bind username:password to the specific variable easily.
pipeline {
agent any
stages {
stage("Using curl example") {
steps {
script {
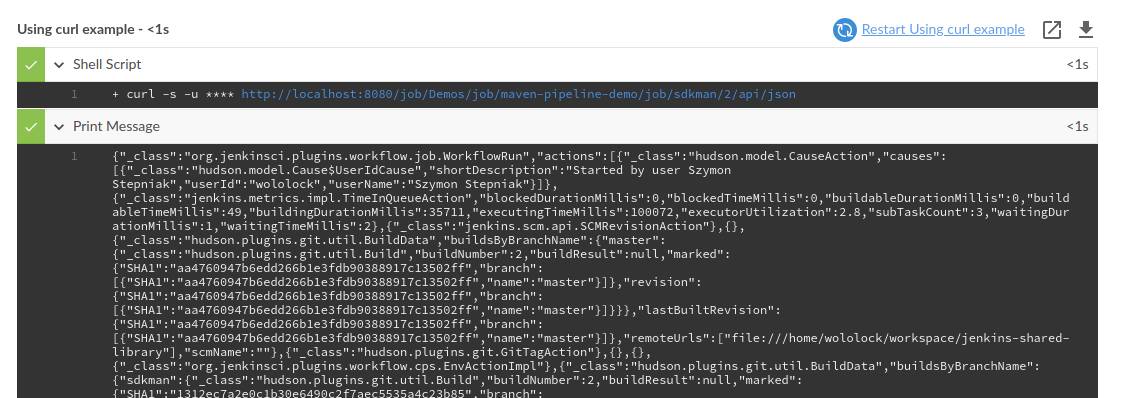
final String url = "http://localhost:8080/job/Demos/job/maven-pipeline-demo/job/sdkman/2/api/json"
withCredentials([usernameColonPassword(credentialsId: "jenkins-api-token", variable: "API_TOKEN")]) {
final String response = sh(script: "curl -s -u $API_TOKEN $url", returnStdout: true).trim()
echo response
}
}
}
}
}
}
Capturing HTTP response status code and response body
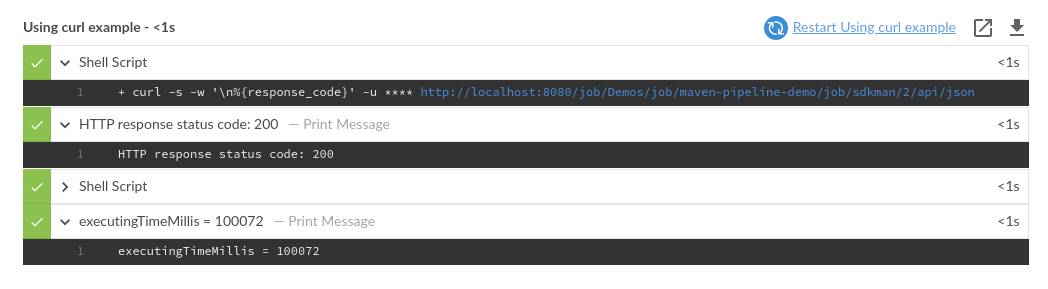
In many cases, you want to react to different HTTP response status codes. For instance, you want to check if the response returned 200 or 400 status code. Let’s extend the previous example to fit into such a use case. We can pass -w' \n%{response_code}' option to change the output format to the one that contains the response body in the first line, and the status code in the second line. Then we can split the output by the new line character, and we can use {multiple-assignment}[Groovy multiple assignment] feature to assign the response body and the status to the two separate variables.
pipeline {
agent any
stages {
stage("Using curl example") {
steps {
script {
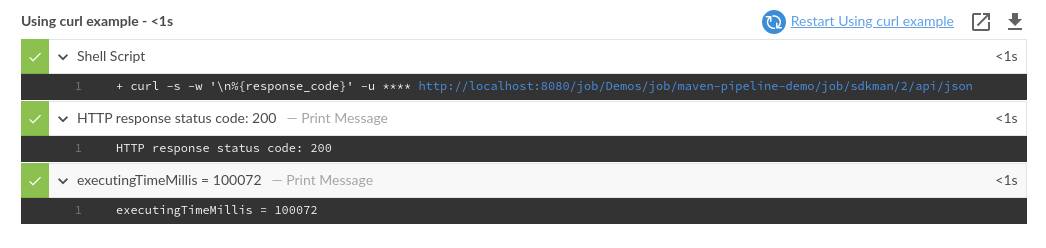
final String url = "http://localhost:8080/job/Demos/job/maven-pipeline-demo/job/sdkman/2/api/json"
withCredentials([usernameColonPassword(credentialsId: "jenkins-api-token", variable: "API_TOKEN")]) {
final def (String response, int code) =
sh(script: "curl -s -w '\\n%{response_code}' -u $API_TOKEN $url", returnStdout: true)
.trim()
.tokenize("\n")
echo "HTTP response status code: $code"
if (code == 200) {
echo response
}
}
}
}
}
}
}
Using groovy.json.JsonSlurperClassic to parse the response
Once we have the response body and the status code extracted, we can parse the JSON body and extract the value we are interested in. The Jenkins build’s JSON API response contains a list of different actions. Let’s say we want to extract the value of executingTimeMillis stored as an action of type jenkins.metrics.impl.TimeInQueueAction.
If you know Groovy, I’m guessing you might already think about using groovy.json.JsonSlurper to solve the problem. It is not a terrible idea, but it has two downsides you need to take into account. Firstly, it makes Jenkins master server involved in parsing the JSON response, even if the stage gets executed on a different node. And secondly, groovy.json.JsonSlurper produces a lazy map which is not-serializable. The first thing might or might not be a problem - it mainly depends on your Jenkins topology architecture. If you use multiple agents to execute stages and have a lot of different Jenkins jobs on your server, it makes sense to utilize Jenkins master server resources more effectively. Using groovy.json.JsonSlurper to parse small JSON documents might not be a bottleneck. Still, if hundreds or thousands of Jenkins jobs start to parse large JSON documents, it may become an issue. The second problem can be solved easily - instead of using groovy.json.JsonSlurper, use groovy.json.JsonSlurperClassic. This class produces a regular hash map that can be serialized, and that way, you can avoid pipeline serialization problems.
pipeline {
agent any
stages {
stage("Using curl example") {
steps {
script {
final String url = "http://localhost:8080/job/Demos/job/maven-pipeline-demo/job/sdkman/2/api/json"
withCredentials([usernameColonPassword(credentialsId: "jenkins-api-token", variable: "API_TOKEN")]) {
final def (String response, int code) =
sh(script: "curl -s -w '\\n%{response_code}' -u $API_TOKEN $url", returnStdout: true)
.trim()
.tokenize("\n")
echo "HTTP response status code: $code"
if (code == 200) {
def json = new groovy.json.JsonSlurperClassic().parseText(response)
def executingTimeMillis = json.actions.find { it._class == "jenkins.metrics.impl.TimeInQueueAction" }.executingTimeMillis
echo "executingTimeMillis = $executingTimeMillis"
}
}
}
}
}
}
}By default, using  |
Using jq to parse the response
There is an alternative, and it is usually a more recommended way to parse and extract values from the JSON data - the jq command-line tool. All you have to do is to make sure that the jq is installed on the Jenkins node that executes the pipeline.
Let’s take a look at how we can use it to extract the same information from the JSON response.
In the below example, I want re-use the However, it is a common pattern to pipe |
pipeline {
agent any
stages {
stage("Using curl example") {
steps {
script {
final String url = "http://localhost:8080/job/Demos/job/maven-pipeline-demo/job/sdkman/2/api/json"
withCredentials([usernameColonPassword(credentialsId: "jenkins-api-token", variable: "API_TOKEN")]) {
final def (String response, int code) =
sh(script: "curl -s -w '\\n%{response_code}' -u $API_TOKEN $url", returnStdout: true)
.trim()
.tokenize("\n")
echo "HTTP response status code: $code"
if (code == 200) {
def executingTimeMillis = sh(script: "echo '$response' | jq -r '.actions[] | select(._class == \"jenkins.metrics.impl.TimeInQueueAction\") | .executingTimeMillis'", returnStdout: true).trim()
echo "executingTimeMillis = $executingTimeMillis"
}
}
}
}
}
}
}
You can learn more about jq from my jq cookbook blog posts series. |
Bonus: a few more useful curl parameters
The list of all available options and parameters that the curl command supports is enormous. You can find all of them in the man curl manual page. Below you can find a few more useful options you may want to use in your Jenkins pipeline.
How to set the Accept:application/json header?
Some REST API endpoints support multiple content types. If this is your case, you will need to explicitly say what the content type you can accept is. For the JSON content type, you will need to pass the -H "Accept: application/json" parameter.
sh(script: "curl -s -H 'Accept:application/json' $url", returnStdout: true).trim()How to store and send cookies from a file?
Cookies are useful for storing temporary information. By default, curl makes all requests in a stateless manner. If you want to store cookies coming with the response, and then send them back with the following request, you may want to add -c cookies.txt -b cookies.txt parameters.
sh(script: "curl -s -c cookies.txt -b cookies.txt $url", returnStdout: true).trim()How to handle redirects (e.g. from http to https)?
If you want to instruct the curl command to follow redirects, you need to add -L parameter.
sh(script: "curl -s -L $url", returnStdout: true).trim()How to retry on connection refused?
The first fallacy of the distributed computing says that "The network is reliable." We all know it is not. The curl command allows you to perform a simple retry mechanism on connection refused error. For instance, if you want to retry up to 10 times with the 6 seconds delay between every retry, you need to add the following parameters: --retry-connrefused --retry 10 --retry-delay 6
sh(script: "curl -s --retry-connrefused --retry 10 --retry-delay 6 $url", returnStdout: true).trim()
Jenkins Declarative Pipeline vs Scripted Pipeline - 4 key differences | #jenkinspipeline
Jenkins Pipeline as a code is a new standard for defining continuous integration and delivery pipelines in Jenkins. The scripted pipeline was the first implementation of the pipeline as a code standard. The later one, the declarative pipeline, slowly becomes a standard of how Jenkins users define their pipeline logic. In this tutorial video, I explain what are four major differences between Jenkins declarative pipeline and the scripted one. Enjoy and don't forget to like and comment on the video! Watch now »

0 Comments