Parsing JSON in command-line with jq: basic filters and functions (part 1)
Have you ever wondered, what is the most convenient way to parse JSON data in the Unix/Linux command line? For instance, how to parse some information from the curl JSON response? Grep? No, thank you. There is a better tool for that. And it’s called jq.
- Author
- Published
- Reading time12 minutes
- Discussion

Welcome to the first episode of the jq cookbook series! The first episode is not about theory - we jump to the first exercise in just a second. I strongly encourage you to install jq command-line tool in your operating system and follow me. There are some exciting things to learn today, and we are starting right now!
- Introduction
- Invoking
jq - Processing input from command other than
curl - Extracting fields from the array
- Filtering
nullvalues withselect(expr)filter - Sorting by field with
sort_by(expr)filter - Limiting the size of the result with
limit(n;expr)filter - Grouping by using
group_by(expr)filter - Putting it all together
Introduction
In this blog post, I will use openlibrary.org public Search API. The reason for that is simple - it returns quite complex and interesting data we can process, and it still mimics a real-life example. I want to use this API to run a full-text search query. I’m going to use my last name as a search term - it is not a very popular Polish last name, so there shouldn’t be many results associated with it.
| The JSON response used in this example is 3631 lines long. To keep all code samples clear, I will limit the JSON output to max. 10-15 lines. The original document can be found here - openlibrary.json. |
$ curl -s "http://openlibrary.org/search.json?q=st%C4%99pniak"
{
"start": 0,
"num_found": 44,
"numFound": 44,
"docs": [
...
]
}My last name contains Polish letter ę, which gets encoded as %C4%99. |
Invoking jq
Once we have the JSON document to process, it’s time to invoke jq processor. The simplest way to do it is to pipe the output from the curl command to the jq input.
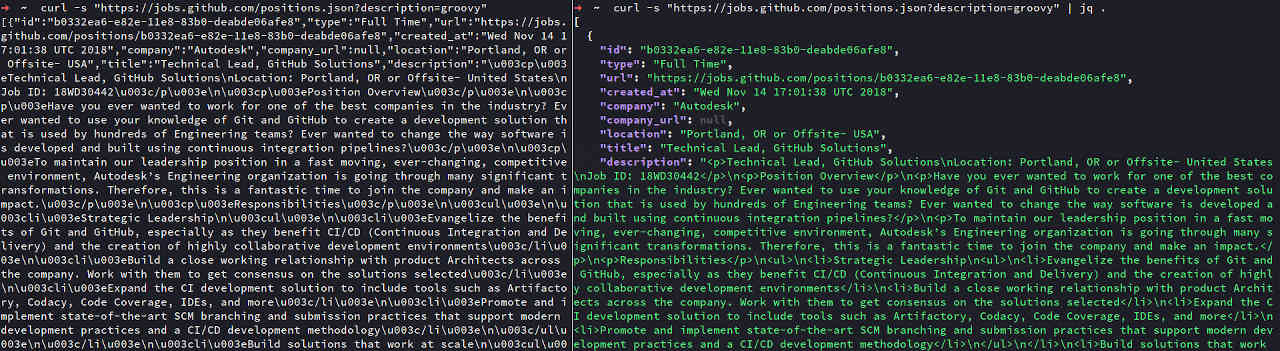
curl to jq example.$ curl -s "http://openlibrary.org/search.json?q=st%C4%99pniak" | jq .The . in the jq filter means identity. |
This simple pipe doesn’t do much, and jq just prints the JSON "as is." However, there is one difference when compared with the plain curl response. jq by default prints JSON document using "pretty" format, and it adds some basic colors.
Processing input from command other than curl
Using pipes comes with huge benefits - it doesn’t matter what command produces the input. It means that we can forward the curl command output to a file, and then use this file to produce input for the jq processor. This might be very useful when we do experiments, and we don’t want to download the same JSON document over and over again.
curl output to the openlibrary.json file$ curl -s "http://openlibrary.org/search.json?q=st%C4%99pniak" > openlibrary.jsonOnce we captured the input, we can e.g., pipe commands cat and jq to produce the same result, but this time without involving the call over the network.
cat to jq example.$ cat openlibrary.json | jq .However, using cat is not necessary if we want to read the input from a file - jq takes a file as an argument as well. In the all upcoming examples, I will use this syntax to save a few characters.
$ jq . openlibrary.jsonExtracting fields from the array
Let’s start processing the data with some real filters. The document we took from the openlibrary.org Search API has a list under the docs key. This list contains all documents matching the search term. Every document is described using multiple fields, but we are interested in the title, author_name, and publish_year only.
The first filter we want to use is called array/object value iterator .[]. This filter extracts values from the given array (or object), so the next filter in the pipeline gets applied to each element. In our case, we want to apply .docs[] filter to extract documents.
docs key.$ jq '.docs[]' openlibrary.json
{
"title_suggest": "Słownik tajemnych gwar przestępczych",
"edition_key": [
"OL1174034M"
],
"isbn": [
"9781859170069",
"1859170064"
],
....The next step is to extract only specific fields. jq filters support piping to apply new filters on top of the results from the previous ones. It uses the same | symbol, but pay attention to one significant difference - piping filters happens inside the jq argument string.
jq filters to extract specific fields.$ jq '.docs[] | {title,author_name,publish_year}' openlibrary.json
{
"title": "Słownik tajemnych gwar przestępczych",
"author_name": [
"Klemens Stępniak"
],
"publish_year": [
1993
]
}
{
"title": "EU adjustment to eastern enlargement",
"author_name": null,
"publish_year": [
1998
]
}
...Looks good. Every document got extracted to the new one, containing only three fields. However, author_name and publish_year seem to be arrays. We can update the filter to extract the first value from those arrays and store them as scalar values instead.
$ jq '.docs[] | {title,author_name: .author_name[0], publish_year: .publish_year[0]}' openlibrary.json
{
"title": "Słownik tajemnych gwar przestępczych",
"author_name": "Klemens Stępniak",
"publish_year": 1993
}
{
"title": "EU adjustment to eastern enlargement",
"author_name": null,
"publish_year": 1998
}
...I guess you already noticed that we can transform objects either by just referring to the field name (e.g. title) or by constructing the new field explicitly (e.g. author_name: .author_name[0].)
Filtering null values with select(expr) filter
When I looked at the response, I noticed that some documents were missing either author_name or publish_year. We can exclude such documents from the final result using the select(expr) filter.
null values.$ jq '.docs[] | {title,author_name: .author_name[0], publish_year: .publish_year[0]} | select(.author_name!=null and .publish_year!=null)' openlibrary.json
{
"title": "Słownik tajemnych gwar przestępczych",
"author_name": "Klemens Stępniak",
"publish_year": 1993
}
{
"title": "Integracja regionalna i transfer kapitału",
"author_name": "Andrzej Stępniak",
"publish_year": 1996
}
...Sorting by field with sort_by(expr) filter
Now let’s say we want to get the result in a specific order. What if we want to sort the final result by publish_year? jq offer the sort_by(expr) filter, but before we apply it, we need to make one modification. The sort_by(expr) filter works on arrays, and our current output is not an array. If you look closely, you will see that this is just a set of JSON documents printed one after another. We can transform it into a JSON array by wrapping our current long filter with square brackets - an array constructor.
Compare the following example with the previous one and spot the difference.
[] constructor.$ jq '[.docs[] | {title,author_name: .author_name[0], publish_year: .publish_year[0]} | select(.author_name!=null and .publish_year!=null)]' openlibrary.json
[
{
"title": "Słownik tajemnych gwar przestępczych",
"author_name": "Klemens Stępniak",
"publish_year": 1993
},
{
"title": "Integracja regionalna i transfer kapitału",
"author_name": "Andrzej Stępniak",
"publish_year": 1996
},
...
]Once we have a JSON array constructed, we can pipe sort_by(.publish_year) into our filter.
sort_by(expr).$ jq '[.docs[] | {title,author_name: .author_name[0], publish_year: .publish_year[0]} | select(.author_name!=null and .publish_year!=null)] | sort_by(.publish_year)' openlibrary.json
[
{
"title": "Rada Portu i Dróg Wodnych w Wolnym Mieście Gdańsku. Gdańsku",
"author_name": "Henryk Stępniak",
"publish_year": 1971
},
{
"title": "Potrącenie w systemie polskiego prawa cywilnego",
"author_name": "Lechosław Stępniak",
"publish_year": 1975
},
{
"title": "Uzdatnianie złomu poprodukcyjnego",
"author_name": "Stanisław Stępniak",
"publish_year": 1978
},
...
]By default, sort_by(expr) sorts objects in the ascending order. To sort objects in the descending order, we can pipe reverse filter after the sort_by(expr) one.
$ jq '[.docs[] | {title,author_name: .author_name[0], publish_year: .publish_year[0]} | select(.author_name!=null and .publish_year!=null)] | sort_by(.publish_year) | reverse' openlibrary.json
[
{
"title": "Dziedzictwo archiwalne we współpracy Polski i Ukrainy",
"author_name": "Władysław Stępniak",
"publish_year": 2010
},
{
"title": "Misja Służby Więziennej a jej zadania wobec aktualnej polityki karnej i oczekiwań społecznych",
"author_name": "Polski Kongres Penitencjarny (4th 2008 Poznań, Poland)",
"publish_year": 2008
},
{
"title": "Czarny Bór",
"author_name": "Władysław Stępniak",
"publish_year": 2007
},
...
]Limiting the size of the result with limit(n;expr) filter
As the next step, we may want to limit the size of the result. Let’s say we want to get the newest three publications as a result. We can use limit(n;expr) filter, but we need to be aware of one thing. To limit the size of an array using this filter, we need to use an expression that extracts values from an array for iteration - .[]. Once limit(n;expr) limits the number of objects, it produces the output in the same format. It means that we don’t get an array but rather a set of separate results instead.
limit(3;.[]) filter.$ jq '[.docs[] | {title,author_name: .author_name[0], publish_year: .publish_year[0]} | select(.author_name!=null and .publish_year!=null)] | sort_by(.publish_year)| reverse | limit(3;.[])' openlibrary.json
{
"title": "Dziedzictwo archiwalne we współpracy Polski i Ukrainy",
"author_name": "Władysław Stępniak",
"publish_year": 2010
}
{
"title": "Misja Służby Więziennej a jej zadania wobec aktualnej polityki karnej i oczekiwań społecznych",
"author_name": "Polski Kongres Penitencjarny (4th 2008 Poznań, Poland)",
"publish_year": 2008
}
{
"title": "Czarny Bór",
"author_name": "Władysław Stępniak",
"publish_year": 2007
}If we want to represent the result as a JSON array, we need to wrap limit(n;expr) filter with [] to construct an array again.
$ jq '[.docs[] | {title,author_name: .author_name[0], publish_year: .publish_year[0]} | select(.author_name!=null and .publish_year!=null)] | sort_by(.publish_year)| reverse | [limit(3;.[])]' openlibrary.json
[
{
"title": "Dziedzictwo archiwalne we współpracy Polski i Ukrainy",
"author_name": "Władysław Stępniak",
"publish_year": 2010
},
{
"title": "Misja Służby Więziennej a jej zadania wobec aktualnej polityki karnej i oczekiwań społecznych",
"author_name": "Polski Kongres Penitencjarny (4th 2008 Poznań, Poland)",
"publish_year": 2008
},
{
"title": "Czarny Bór",
"author_name": "Władysław Stępniak",
"publish_year": 2007
}
]
Parsing JSON from curl with jq: sort_by, group_by, limit (part 1) | #jq #json #curl
In this video, I show you how to use the jq command-line to parse and transform a JSON response to the desired format. I use openlibrary.org Search API to get a complex JSON document (~3600 lines) using curl command for further parsing using jq. In the first step, we extract three fields for each document (title, author, publishing year) and then we continue transforming the JSON - we sort it, we limit the number of elements, and last but not least, we group elements by the author name. Watch now »
Grouping by using group_by(expr) filter
Let’s say we want to find out how many publications each author created. jq offers built-in group_by(expr) filter we can use. In our case, we will use group_by(.author_name) to group all publications by their authors.
group_by(.author_name) filter.$ jq '[.docs[] | {title,author_name: .author_name[0], publish_year: .publish_year[0]} | select(.author_name!=null and .publish_year!=null)] | group_by(.author_name)' openlibrary.json
[
[
{
"title": "Integracja regionalna i transfer kapitału",
"author_name": "Andrzej Stępniak",
"publish_year": 1996
},
{
"title": "Promocja polskich podmiotów inwestycyjnych na obszarze Wspólnot Europejskich",
"author_name": "Andrzej Stępniak",
"publish_year": 1993
},
{
"title": "Kwestia narodowa a społeczna na Śląsku Cieszyńskim pod koniec XIX i w początkach XX wieku, do 1920 roku",
"author_name": "Andrzej Stępniak",
"publish_year": 1986
},
{
"title": "Polska-WE",
"author_name": "Andrzej Stępniak",
"publish_year": 1993
}
],
[
{
"title": "Kula jako symbol vanitas",
"author_name": "Beata Purc-Stępniak",
"publish_year": 2004
}
],
....
]As you can see now, group_by(.author_name) produced an array of arrays. It’s hard to say how many publications each author did from this document, so we might need to transform this output a bit.
The next filter we need to apply is .[] to start iterating over the grouped arrays. We will pipe this iteration with a transformation that extracts author_name field from the first result using {author_name: .[0].author_name} filter. And as we seen before, .[] | {author_name: .[0].author_name} combination produces a set of results, so we need to wrap it with [] to construct an array.
author_name from the grouped result.$ jq '[.docs[] | {title,author_name: .author_name[0], publish_year: .publish_year[0]} | select(.author_name!=null and .publish_year!=null)] | group_by(.author_name)| [.[] | {author_name: .[0].author_name}]' openlibrary.json
[
{
"author_name": "Andrzej Stępniak"
},
{
"author_name": "Beata Purc-Stępniak"
},
{
"author_name": "Colloquia Jerzy Skowronek dedicata (10th 2004 Warsaw, Poland)"
},
....
]That’s a good step forward - now we have author names extracted from the grouped result. The next step is to update the transformation filter to also produce the count field - a field containing the number of publications. There is a simple way to do it. The current transformation filter, [.[] | {author_name: .[0].author_name}], iterates the nested arrays that contain all documents associated with the same author. It means that . (identity) in this filter refers to a list of objects, and that is why we extract the author name using .[0].author_name expression, which means: take the first object from the array and return its author_name value. We can use this array to count its size. In the jq, we have a filter called length that can be piped with an array to return its size. So in our case, an expression . | lenght used in the context of this transformation will return the size of an array, which represents the number of publications.
length filter.$ jq '[.docs[] | {title,author_name: .author_name[0], publish_year: .publish_year[0]} | select(.author_name!=null and .publish_year!=null)] | group_by(.author_name)| [.[] | {author_name: .[0].author_name, count: . | length}]' openlibrary.json
[
{
"author_name": "Andrzej Stępniak",
"count": 4
},
{
"author_name": "Beata Purc-Stępniak",
"count": 1
},
{
"author_name": "Colloquia Jerzy Skowronek dedicata (10th 2004 Warsaw, Poland)",
"count": 1
},
....
]Voila!
Putting it all together
Let’s finish this experiment by putting all commands we have learned today together. We can add sort_by(expr) and limit(n;expr) to the latest query to produce the final result - an array of three authors that published the most documents.
length filter.$ jq '[.docs[] | {title,author_name: .author_name[0], publish_year: .publish_year[0]} | select(.author_name!=null and .publish_year!=null)] | group_by(.author_name)| [.[] | {author_name: .[0].author_name, count: . | length}] | sort_by(.count) | reverse | [limit(3;.[])]' openlibrary.json
[
{
"author_name": "Władysław Stępniak",
"count": 11
},
{
"author_name": "Andrzej Stępniak",
"count": 4
},
{
"author_name": "Henryk Stępniak",
"count": 3
}
]And that’s it for today. In the next episode, we will dive deeper into more advanced filters and functions that jq offers. Stay tuned!

0 Comments